스케줄링 제어
개요
다시금 정의를 내리자면, 스케줄링은 어떤 노드에 파드를 배치하도록 결정을 내리는 동작을 말한다.
스케줄링에 있어서 고려할 것들은 무엇이 있을까?
- 고가용성 - 여러 노드에 골고루 파드 배치
- 효율성 - 연관성이 깊은 파드들을 같은 노드에 배치
- 자원 분배 - 특정한 자원이 있는 노드는 특정한 파드만 배치
- 보안 - 크리티컬한 파드는 다른 노드로 분리, 혹은 네트워크 트래픽이 외부로 나가지 않게 만들기
클러스터를 운영하는데 있어 관리자는 다양한 지점에서 스케줄링이 일어나도록 고려해야할 필요가 있다.
기본적으로 쿠버네티스에서 제공하는 스케줄링 로직이 존재하나, 여기에 관리자는 다양한 설정을 하여 스케줄링을 제어할 수 있다.
이 문서에서는 전체적인 스케줄링 구조, 기본적으로 제공되는 스케줄링 기법, 스케줄링을 확장하는 기법들을 정리한다.
스케줄링 흐름
파드를 만들라는 명령을 내리면 kube-apiserver는 Etcd에 해당 오브젝트에 대한 내용을 저장한다.
파드가 실제로 어떤 노드에서 실행되기까지, 어떤 과정이 일어나는가?
여기에서 가장 첫 번째로 관여를 하게 되는 컴포넌트가 바로 kube-scheduler이다.[1]
api서버는 단순하게 파드의 정보를 etcd에 저장만 할 뿐이다.
api 서버가 저장한 파드 정보에는 기본적으로 노드에 배치된다(assigned)는 정보가 없다.
스케줄러는 이러한 파드가 있는지 감시하다가, 파드가 어떤 노드에서 실행되는 것이 적합한지 결정을 내리는 동작, 즉 스케줄링을 한다.
스케줄링은 크게는 두 가지 단계로 나뉜다.
필터링(filtering)
이 단계는 어떤 노드들이 배치될 만한지를 선별하는 단계이다.
여기에서 선택된 노드들을 실행 가능한(feasible) 노드라고 부른다.
만약 이 단계에서 남은 노드가 없다면, 해당 파드는 정말 어딘가에 배치될 수 없다는 것을 뜻한다.
스케줄러는 이런 파드를 unschedulable이라고 상태를 업데이트한다.
스코어링(scoring)
선별된 노드들 중에서 어떤 노드가 파드를 실행하기 가장 적합한지 점수를 내는 단계가 스코어링 단계이다.
여기에서 가장 높은 점수를 얻는 노드가 최종적으로 선택된다.
만약 1등 점수를 가진 노드가 여러 개라면 노드는 무작위로 선택될 것이다.
바인딩(binding)
최종 선택된 노드를 파드 정보에 업데이트하는 동작을 바인딩이라고 부른다.
비로소 파드가 어떤 노드에 들어가게 될지 확정되는 순간이다!
이걸 스케줄링의 하나의 단계라 보기는 조금 어려운데, 스케줄링이 완료되고 일어나는 다음 단계라고 보면 될 것 같다.
스케줄링을 확장 커스텀할 때, 이 단계에 대해서도 포인트가 지정된다.
스케줄링 조작
스케줄링을 순전히 스케줄러에게 위임하고 손가락만 빤다면 클러스터를 운영한다고 할 수 없을 것이다.
관리자는 파드, 노드에 다양한 설정을 넣어 스케줄러가 원하는대로 동작하도록 유도하는 게 가능하다.
어떤 파드가 어떤 종류의 노드에 배치되길 희망한다던가(preffered), 제한한다던가(restricted) 하는 설정을 할 수 있다.[2]
nodeName
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: worker1
가장 간단한 방법은 어떤 노드에 배치할지 직접 설정하는 것이다.[3]
보다시피 nodeName을 지정해 대놓고 콕 어떤 노드에 배치하라 지정할 수 있다.
사실 이 경우에는 스케줄링이 된다고 부를 수도 없는 게, 이건 위에서 말한 각종 단계를 거치지 않고 이미 바인딩이 된 것이나 다름없다.
만약 해당 이름을 가진 노드가 없다면?
그냥 파드는 pending 상태로 머물러있다가, 소리 소문 없이 사라져버린다..
해당 노드가 이미 꽉 차있다면?
그럼 파드는 일단 fail이 뜨고, 그 이유가 표시될 것이다.
이런 사용방식은 실무 케이스에서 당연히 좋지도 않고, 그럴 거면 쿠버네티스를 쓸 이유도 그다지 없다..
이런 설정을 직접적으로 넣을 수 있도록 디자인된 이유는, 여러 커스텀 스케줄러를 클러스터에서 운영할 경우 관리가 어려워질 때를 위해서이다.
정말 어떤 파드는 확실하게 관리자가 책임지고 컨트롤해야 한다던가 할 때 모든 스케줄링을 우회하도록 하는 건데, 특별한 케이스가 아니라면 그다지 추천되지 않는다.
간단하다보니 E-nodeName으로 스케줄링 실습을 후딱 진행했다.
nodeSelector
nodeSelector:
disktype: ssd
라벨 셀렉터를 이용해 어떤 라벨을 가진 노드에 배치되도록 제한을 걸 수도 있다.
이 경우에는 라벨을 이용해 아주 강력한 필터링이 걸리는 것이라 보면 된다.
kubernetes.io/hostname 라벨은 노드 이름을 나타내니 이걸로 한 노드만 남기고 전부 필터링해버리는 것도 가능하다.
그래도 이건 스케줄링이 걸리긴 하는 거라 위의 nodeName보다는 훨씬 나은 방식이다.
다만, 라벨이란 것은 항상 변형을 할 수 있기도 하고 다양한 클라우드 환경마다 이 값이 항상 노드의 이름을 나타내는 게 아닐 수도 있어서 주의가 필요하다.
NodeRestriction 승인 제어 플러그인을 사용하면 kubelet이 임의로 노드의 라벨을 바꾸는 것을 막을 수 있다.
node-restriction.kubernetes.io/라는 접두사가 붙는 라벨을 노드에 붙이면 이 값은 사용자가 아닌 이상 절대 수정할 수 없다.
kubelet은 간혹 노드의 상태를 업데이트하면서 노드 라벨을 수정하기도 하는데, 이것이 막히게 되는 것이다.
affinity
어피니티는 파드가 어떤 노드에 배치될지 선호하거나, 제한을 해버리는 설정 방법이다.
자세한 건 어피니티 문서 참고.
topology spread contraints
지정한 파드들을 여러 노드에 최대한 분산시켜서 배치하고 싶을 때 거는 설정 방법이다.
가령 10개의 노드가 있는 클러스터에서 디플로이먼트로 10개의 파드를 배치한다고 쳐보자.
이때 상황에 따라 다르겠지만, 이 10개가 한 노드에 배치될 수도 있고, 3개의 노드에만 배치될 수도 있다.
이럴 때 확실하게 노드에 분산 배치되도록 설정하는 것이 바로 토폴로지 분산 제약 방식이다!
자세한 건 Topology Spread Constraints 참고.
taint & toleration
이건 노드에 얼룩을 칠하고, 이 얼룩을 용인하는 파드만 배치할 수 있도록 필터링 단계를 관리하는 기법이다.
테인트, 톨러레이션 참고.
스케줄링 프레임워크
스케줄링은 관리자가 커스텀하고 확장할 수 있도록 플러그인을 넣을 수 있는 구조로 디자인됐다.[4]
그래서 전헤 흐름에서 몇가지 구획을 나눠 확장 포인트를 노출하고 있으며, 이를 이용해 스케줄링을 자유롭게 조정할 수 있다.
이러한 스케줄링의 확장 가능한 아키텍처를 통틀어 스케줄링 프레임워크라고 부른다.
전체 흐름
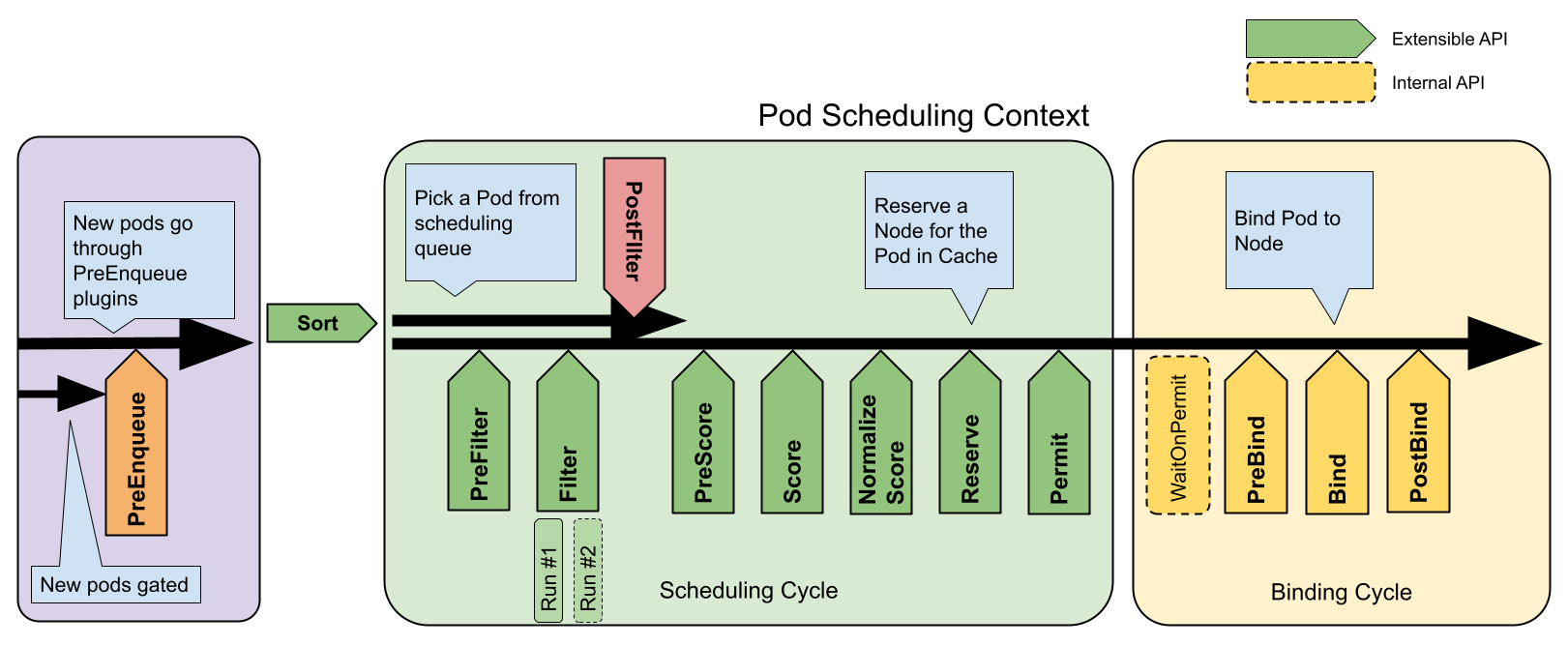
이 사진에 존재하는 각 화살표가 확장 포인트라고 보면 된다.
사실 스케줄링이라는 것은 구조적으로 말하자면, 각 확장 포인트에 여러 스케줄링 플러그인이 주입되어 적용되는 형태인 것이다.
스케줄링 사이클과 바인딩 사이클로 나뉘는데, 이둘을 합쳐 스케줄링 컨텍스트라고 부른다.
스케줄링은 직렬이지만 바인딩으 동시 실행이 가능하다.
각 포인트에 대한 자세한 설명은 생략하고, 대신 스케줄러 설정에서 다룰 수 있는 포인트들만 간단하게 짚겠다.[5]
- queueSort
- 스케줄링 큐의 파드들을 정렬한다.
- 한번에 한 플러그인만 들어갈 수 있다.
- preFilter
- 필터링을 들어가기 이전에 파드의 정보를 확인한다.
- 여기에서 아예 파드를 unschedulable 상태로 만들 수 있다.
- filter
- 파드가 배치될 수 없는 노드를 필터링하는 부분이다.
- postFilter
- 만약 배치될 수 있는 노드가 없다면 호출된다.
- 여기에서 파드를 schedulable이라고 세팅하면 다른 postFilter 플러그인들은 호출되지 않는다.
- preScore
- 스코어링 작업을 하기 이전에 정보를 전달해줄 수 있는 포인트
- score
- 스코어링을 하는 포인트이다.
- reserve
- 파드를 위해 예약된 자원 정보를 볼 수 있는 포인트
- 여기에 Unreserve 호출에 대한 정의를 해서 예약이 안됐을 때를 보는 것도 가능하다.
- permit
- 실제로 파드가 바인딩 되기 이전에 지연을 줄 수 있는 포인트
- preBind
- 바인딩이 되기 이전 필요한 작업을 수행할 수 있는 포인트
- bind
- 노드에 파드를 바인딩하는 포인트.
- 순서대로 호출되며 한 플러그인이라도 바인딩을 하면 다음 것들은 스킵된다.
- 최소한 하나는 무조건 필요하다.
- postBind
- 파드가 바인딩되고나서 정보를 볼 수 있는 포인트
- multiPoint
- 이건 실제 단계가 아니라 설정 상의 필드이다.
- 위에 여러 포인트 여러 개를 한꺼번에 호출할 때 쓴다.
양식 작성법
스케줄러 설정은 형식이 꽤나 역동적이다.
그래서 전체적으로 짚을 만한 포인트를 위주로 정리를 한다.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
percentageOfNodestoScore: 30 # 전체 노드 중 몇 퍼센트까지 골라내면 바로 스코어링 들어갈지.
profiles:
- schedulerName: default-scheduler
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
- schedulerName: custom-scheduler
plugins:
score:
disabled:
- name: PodTopologySpread
enabled:
- name: MyCustomPluginA
weight: 2
- name: MyCustomPluginB
weight: 1
profiles라는 필드에 여러 스케줄러를 설정할 수 있다.
이때 각 스케줄러는 schedulerName을 가진다(default만 있으면 굳이 안 써도 되긴 함).
그리고 plugins 필드에 각종 플러그인들이 스케줄링에 어떻게 쓰일지 명시해준다.
설정할 때는 plugins 필드에 각 포인트에 넣고 싶은 건 enabled, 빼고 싶은 건 disabled라고 해주면 된다.
score의 경우 점수를 매기는 것이기 때문에 보다시피 weight라는 필드는 적용될 순서를 나타내는 필드이다.
높은 점수를 가진 플러그인이 먼저 적용되게 된다.
pluginConfig에서는 각 플러그인 별 세팅을 하고 싶은 것들을 넣어주면 된다.
이건 각 플러그인마다 세팅법이 전부 다르니 문서를 참고하자.
유의점 중 하나는, 여러 스케줄러를 쓴다고 해도 queueSort는 무조건 다 똑같은 것을 써야 한다는 것이다.
어차피 큐 자체는 하나밖에 없기 때문이다.
multiPoint
profiles:
- schedulerName: non-multipoint-scheduler
plugins:
score:
enabled:
- name: MyPlugin
filter:
enabled:
- name: MyPlugin
---
profiles:
- schedulerName: multipoint-scheduler
plugins:
multiPoint:
enabled:
- name: MyPlugin
멀티 포인트는 이런 식으로 쓴다.
여기에 MyPlugin이 score, filter에 대한 포인트를 구현해두고 있다면, 위 설정과 아래 설정은 똑같이 동작할 것이다.
멀티 포인트의 장점은 이런 플러그인이 추후에 확장 포인트를 더 둔다고 했을 때 그것이 자동으로 반영된다는 점.
근데 disabled[].name: '*'를 하는 포인트가 있다면 멀티포인트로 둔 플러그인도 같이 영향을 받으니 주의하자.
weight
weight라는 필드는 가중치이면서, 순서를 매기는 필드이다.
여러 플러그인이 하나의 포인트에 들어갈 때 어떤 플러그인이 먼저 적용될지를 정할 때 weight를 써주면 된다.
score 포인트의 경우에 이것은 실제로 가중치로도 작용한다.
기본적으로 각 포인트에서 플러그인이 적용되는 순서는 이런 순서를 따른다.
- 명시적으로 확장 포인트가 지정된 플러그인
- 멀티포인트로 지정된 플러그인
- 기본 플러그인
기본 플러그인들은 직접적으로 비활성화해야만 안 쓰인다.
말로만 보면 어려우니 예시를 들어보자.

플러그인이 이렇게 있고, 각각의 확장 포인트가 이런 식이라고 해보자.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: multipoint-scheduler
plugins:
multiPoint:
enabled:
- name: 'CustomQueueSort'
- name: 'CustomPlugin1'
weight: 3
- name: 'CustomPlugin2'
disabled:
- name: 'DefaultQueueSort'
filter:
disabled:
- name: 'DefaultPlugin1'
score:
enabled:
- name: 'DefaultPlugin2'
이때 이런 식의 설정은 각 포인트에서 어떻게 동작할까?
- QueueSort
- DefaultQueueSort는 비활성화됐다.
- CustomQueueSort만 실행된다(위에서도 언급했듯이 QueueSort는 하나만 있을 수 있다).
- Filter
- DefaultPlugin1은 비활성화됐다.
- CustomPlugin1이 가중치가 3이므로 먼저 실행된다.
- 그 다음 CustomPlugin2가 실행된다.
- Score
- 비활성화된 플러그인이 없다.
- 명시적으로 포인트가 지정된 DefaultPlugin2가 먼저 실행된다(명시함으로 인해 기본 플러그인이 앞순서로 정해짐).
- 가중치가 3인 CustomPlugin1이 다음 실행된다.
- CustomPlugin2가 실행된다.
- 마지막으로 DefaultPlugin1이 실행된다.
특정 포인트에 정확하게 명시를 하는 것이 순서를 항상 높게 받는다는 것을 명심하자.
또, 기본적으로는 기본 플러그인이 가장 후순위라는 것도 알아두면 크게 어렵지는 않다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| PDB | knowledge | 2024-08-31 |
| Quality of Service | knowledge | 2025-03-09 |
| 어피니티 | knowledge | 2025-04-18 |
| Affinity | knowledge | 2025-03-19 |
| Topology Spread Constraints | knowledge | 2025-03-19 |
| Scheduling Gates | knowledge | 2025-03-19 |
| kube-scheduler | knowledge | 2025-03-19 |
| 테인트, 톨러레이션 | knowledge | 2025-03-19 |
| 스케줄링 제어 | knowledge | 2025-03-20 |
| 파드 중단 | knowledge | 2025-03-20 |
| 쿠버 스케줄러 시뮬레이터 소개 | knowledge | 2025-04-08 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | published | 2025-03-22 |
| E-nodeName으로 스케줄링 실습 | topic/explain | 2025-03-19 |
참고
https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/ ↩︎
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/ ↩︎
https://kubernetes.io/docs/tasks/configure-pod-container/assign-pods-nodes/ ↩︎
https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/ ↩︎
https://kubernetes.io/docs/reference/scheduling/config/#scheduling-plugins ↩︎